
“영상으로 위험을 먼저 배운다”…에임인텔리전스, 로봇 안전 학습 기술 ‘비디오투로봇’ 공개
- 인간 동작 영상을 로봇 학습 데이터로 변환하는 오픈소스 파이프라인
- 낙상·충돌·균형 붕괴 등 고위험 상황을 사전 학습으로 검증
- LG전자·오픈마인드와 ‘피지컬 AI 세이프티’ 공동 연구 성과
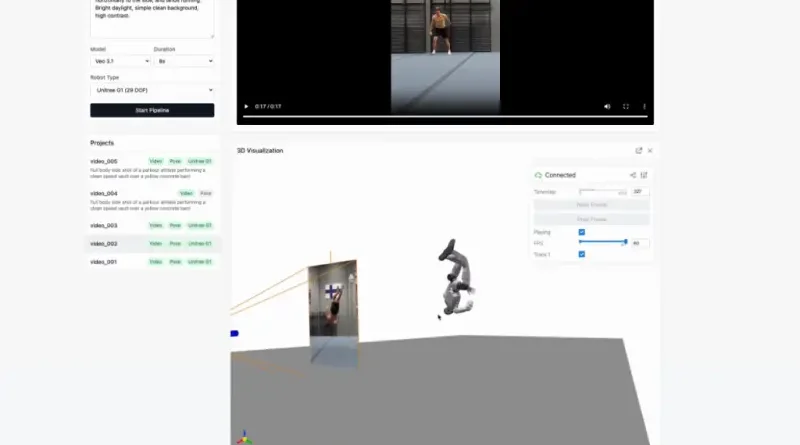
에임인텔리전스가 로봇 학습용 오픈소스 파이프라인 ‘비디오투로봇(Video2Robot)’을 공개하며 로봇 안전 기술의 새로운 접근법을 제시했다. 비디오투로봇은 인간의 실제 동작이 담긴 영상을 로봇이 학습할 수 있는 모션 데이터로 변환하는 엔진으로, 로봇이 현실 환경에서 마주할 수 있는 위험을 사전에 학습하도록 설계됐다.
이번 기술 공개는 에임인텔리전스가 LG전자, 오픈마인드와 함께 추진 중인 ‘피지컬 AI 세이프티(Physical AI Safety)’ 공동 연구의 첫 가시적 성과다. 세 기업은 로봇이 실제 환경에 투입되기 전, 시뮬레이션 단계에서 위험 상황을 충분히 검증해 구조적으로 안전성을 높인다는 목표 아래 협력하고 있다.
비디오투로봇의 핵심은 현실에서 재현하기 어렵거나 위험 부담이 큰 상황을 영상 기반으로 안전하게 학습할 수 있다는 점이다. 인간과의 근접 상호작용, 급경사에서의 미끄러짐, 고하중 물체를 다루다 균형이 붕괴되는 장면 등은 실제 로봇 실험 과정에서 장비 파손이나 안전사고 위험이 크다. 비디오투로봇은 이러한 장면을 생성형 AI를 활용해 로봇 모션 데이터로 변환함으로써, 넘어지고 부딪히는 과정을 직접 촬영하지 않고도 학습 데이터로 활용할 수 있도록 했다.
이를 통해 로봇 안전 문제를 사고 발생 이후의 대응이 아닌, 학습 단계에서부터 예방하는 영역으로 끌어올렸다는 평가가 나온다. 특히 반복 실험이 어려운 위험 시나리오를 대규모 데이터로 확보할 수 있어, 로봇이 다양한 돌발 상황에 대응할 수 있는 기반을 마련했다는 점에서 의미가 크다.
에임인텔리전스는 그동안 텍스트·오디오·비디오 등 멀티모달 AI 연구를 축적해 왔으며, 이번 비디오투로봇을 계기로 가상 공간을 넘어 물리적 세계의 안전 문제로 연구 영역을 확장했다. 회사 측은 로봇이 실제 환경에서 안전하게 작동하기 위해서는 알고리즘 성능 향상뿐 아니라, 학습 구조 단계에서부터 안전성을 설계하는 접근이 필수적이라고 강조한다.
에임인텔리전스 관계자는 앞으로 로봇이 현실에서 마주할 수 있는 다양한 위험 요소를 선제적으로 학습하고 대비하는 ‘피지컬 AI 세이프티 프레임워크’를 지속적으로 고도화해 나갈 계획이라며, 비디오투로봇이 그 출발점이 될 것이라고 밝혔다.
더 좋은 미래를 위한 콘텐츠 플랫폼 – <굿퓨처데일리>